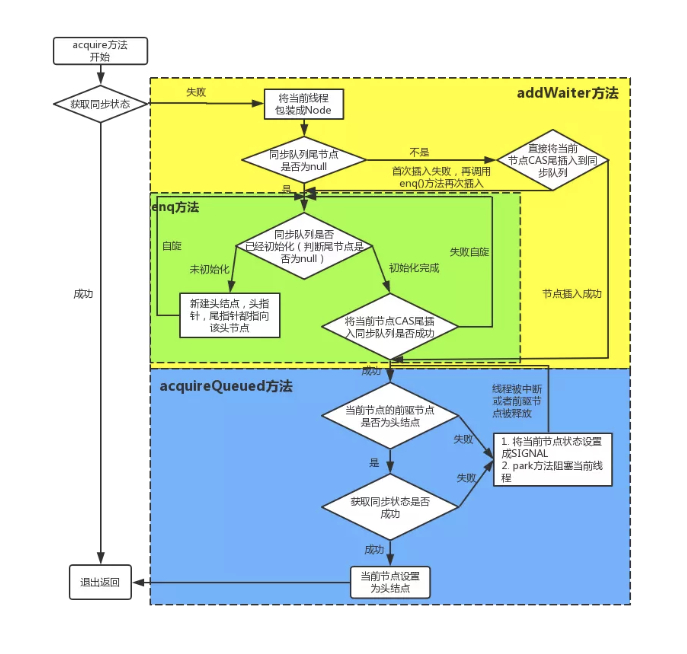
一、《双塔模型的瓶颈究竟在哪?》
文章介绍了谷歌的一篇论文,《Large Dual Encoders Are Generalizable Retrievers》
文章主要在讲,稠密检索模型在OOD(Out-Of-Distribution,即域外)泛化能力不行,主要还是模型规模和训练数据的问题。
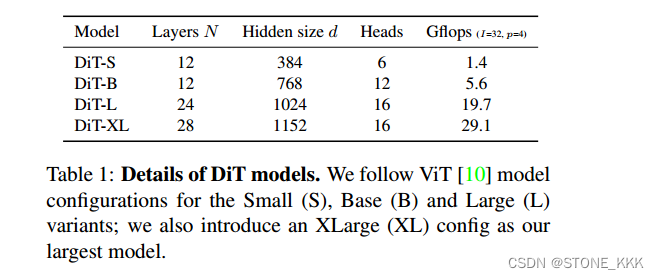
文章在固定稠密向量维度不变的条件下,采用不同尺寸的T5-encoder(base、large、3B、11B)训练稠密检索模型。实验结果表明,“稠密检索模型的瓶颈并不完全在于单个向量的表示能力不足,编码器的能力也会在很大程度上影响模型的泛化能力。”
文章中模型的损失函数,使用了余弦相似度,而不是点积相似度。针对“使用余弦相似度度量训练的模型会偏向于检索出短文档,而使用点积相似度训练的模型会偏向于检索出长文档”,文章验证当模型尺寸变大之后,这一论点是否还成立。结论是当模型尺寸变大之后,模型能够生成更优质的文档编码,长度偏差问题就没那么严重了。
借助kimi,学习了文章中两个相关知识:BM25和稠密检索模型
BM25

稠密检索模型(Dense Retriever)是自然语言处理(NLP)和信息检索领域中的一个术语,它指的是一种基于密集向量表示的文档检索方法。这种模型之所以被称为“稠密”(Dense),是因为它们使用连续的、稠密的向量(通常是实数向量)来表示查询(query)和文档(document),而不是传统的稀疏向量表示。
在传统的信息检索系统中,文档和查询通常是通过稀疏向量表示的,例如使用TF-IDF(词频-逆文档频率)或词袋模型(Bag of Words),其中向量中的每个元素对应于词汇表中的一个单词,并且只有单词出现时元素才非零。
相比之下,稠密检索模型使用深度学习技术,如变换器(Transformers)或BERT(Bidirectional Encoder Representations from Transformers),来生成每个文档和查询的密集向量表示。这些向量能够捕捉到文档和查询之间的语义相似性,因为它们是在连续的向量空间中通过学习大量的文本数据得到的。
稠密向量表示的优势在于:
- 语义相关性:稠密向量能够捕捉到单词和短语之间的语义关系,甚至是词汇表之外的语义信息。
- 计算效率:稠密向量可以通过点积(dot product)或余弦相似度(cosine similarity)快速计算相似性,这在大规模检索任务中非常有用。
- 灵活性:稠密向量可以用于各种不同的任务,包括语义搜索、问答系统和对话系统。
然而,稠密检索模型也有其挑战,比如需要大量的计算资源来训练大型模型,以及可能存在的域外泛化能力问题。文章中提到的研究表明,通过增加模型的大小和提供更多的训练数据,可以提高稠密检索模型的泛化能力。
二、《推荐系统 Wide&Deep 模型详解》
看到上篇文章讲双塔模型,印象中推荐系统也有使用双塔模型,想起之前的一篇文章,一直存着没看。
看了看,发现推荐系统和RAG,果然有很多相似的地方,核心问题都是Retrieval,模型架构里都有Retrieval和重排
三、RAG与推荐系统的相似与不同
借助kimi,理解如下:
推荐系统和RAG(Retrieval-Augmented Generation)确实在某些方面有相似之处,尤其是在处理信息检索和生成任务时。
1. Retrieval(检索)
推荐系统:
- 在推荐系统中,检索步骤通常涉及从大量的候选集中快速找到一小部分与用户相关的项目。这可以通过各种方法实现,如基于内容的推荐、协同过滤、深度学习模型等。
RAG:
- RAG是一种结合了检索和生成的序列生成方法。在检索步骤中,模型会从大量候选文档中检索出与输入查询最相关的文档片段。
2. 重排(Ranking/Re-ranking)
推荐系统:
- 重排步骤是对检索阶段得到的结果进行排序,以确定哪些项目最有可能被用户喜欢或点击。这通常涉及到预测用户对每个项目的兴趣,如使用CTR(点击通过率)模型进行排序。
RAG:
- 在RAG中,重排可能涉及到对检索到的文档片段进行排序,以便选择最相关或最有用的信息来生成回复或续写。
相似之处:
- 信息检索:两者都涉及到从大量数据中检索相关信息的问题。
- 排序机制:都需要对检索到的信息进行排序,以便提供最相关的结果。
- 模型架构:可能会包含相似的组件,如用于编码和检索的神经网络。
不同之处:
尽管有相似之处,但推荐系统和RAG在目标和实现细节上也存在差异:
- 目标差异:推荐系统的目标是预测和推荐用户可能感兴趣的项目,而RAG的目标是生成与输入查询相关的回复或续写。
- 数据类型:推荐系统通常处理用户行为数据和项目特征,而RAG处理的是文本查询和文档。
- 生成阶段:RAG明确包含了一个生成阶段,它使用检索到的信息来生成回复,而推荐系统可能不涉及这一步骤,除非是在生成推荐列表的元数据(如描述)时。
总的来说,尽管推荐系统和RAG在核心的检索和重排步骤上有相似之处,但它们的应用场景、数据处理方式和最终目标有所不同。